In this article, I want to write about why and how I built my web analytics from scratch. I will explain my motivation and walk you through the technical details of the project.
Why to roll your own analytics?
I want to write articles that are useful and insightful. To do that, I need to understand how my content is performing and where it needs to improve. After some consideration, I decided to focus on how much time visitors spend on a page (so-called “time-on-page”). This metric can provide me with valuable feedback. If most of my visitors spend only 10 seconds on an article, maybe, it was not that useful.
I am using Plausible as a web analytics tool for this blog. It provides a way to measure how much time visitors spend on a page. But, it has an issue. When a user visits only a single webpage, the “time-on-page” metric is not calculated (details). Unfortunately, this is the situation with my blog. Most of the visitors visit only one article. Meaning I lose the majority of the valuable insights. Because of that, I decided to build my web analytics project.
Building the project
Before I started building, I decided to create a list of requirements for the MVP version:
-
hosted on a serverless platform; it makes maintenance and scaling easier
-
hosted for free, I am on a tight budget here

-
does not store private data of visitors; no cookies or IP addresses
-
focuses on the “time-on-page” metric only; other features are less important
-
supports a single domain; a multi-domain setup will need more development.
As you can see, I am not building a replacement for Plausible. My only goal was to be able to accurately track the “time-on-page” metric. In the future, if needed, I can add more features or even substitute Plausible completely.
Let’s dive into the technical details.
Web browser tracker
The main idea of how a tracker should work came from an article from the Ctrl blog. They described their experience in building web analytics from scratch.
The tracker is a short script written in plain JavaScript. It detects when a visitor opens or closes a page and notifies the backend. When the page opens, the script will generate a random UUID in the browser called tracking_id.
The tracking_id is unique for every visited page, and not preserved in cookies or localStorage. This is not a solid design, but for the MVP version, it is good enough.
The tracking starts only after 10 seconds to drop bots or tabs opened on accident.
When tracking, the script will listen to visibilitychange event:
document.addEventListener("visibilitychange", () => {
let state = document.visiblityState;
sendEvent(state);
});
This event is triggered when visibilityState changes. The state has two values:
-
visible, means that the page is the foreground tab of a non-minimized window
-
hidden, means that the document is either a background tab or part of a minimized window.
On state change, the script will send an HTTP request to the backend using fetch API. It will contain necessary information like the current page URL, tracking_id, etc.
You need to set the keepalive parameter to true in fetch API. This will ensure that the last request finishes when the page is closed.
Note: The beacon API is not used to send requests because ad blockers can block it.
In the end, you will end up with a sequence of events coming for each page visitor like this:
visible
hidden
visible
hidden
It is enough to calculate a time difference between each visible/hidden pair and sum it up to get a final time for a particular visitor.
Backend
It was easy to decide on which serverless platform to host my web analytics project. For a long time, I heard a lot of good things about Cloudflare Workers. This was a perfect opportunity to try it out. Workers have a lot of benefits like easy deployment, scalable, and a good free tier plan.
Besides, Workers have a few handy features that might be useful for the future. For example, each HTTP request contains information about the request’s origin and bot score.
My programming language of choice for Workers was TypeScript. Something I also wanted to try for a long time.
Storage
My website traffic is low, but I still want to build a web analytics that can potentially scale in the future. It means choosing appropriate storage.
I assume that there will be many more “write” requests (new visitors coming) than “read” requests. So I need write-optimized storage.
Also, there is one more limitation that comes from the Cloudflare Workers. Due to their nature, handling TCP connections requires an extra setup. I didn’t want to add more complexity. It meant my storage choices were limited to the serverless databases that support HTTP connections.
Initially, I wanted to stay with the Cloudflare products, so I looked into the KV store (Key-Value storage). But the KV store is optimized for “read” operations and not “write” operations. It is reflected in its free tier (only 1000 writes per day). Plus all data analytics will need to be handled inside Cloudflare Worker. It will increase usage and, probably, hit free tier limits.
Then, I found an article about Cloudflare serverless database partners. It lists a few storage solutions like Macromenta and Fauna that work well with Workers.
When checking the Macromenta website, I found a broken documentation website. So, I switched to Fauna.
Note: As of the time of writing this article, looks like the Macromenta documentation page is working fine.
Fauna has a nice interface and easy setup. It was my first choice. The first version of the project was based on Fauna. The biggest issue for me was the steep learning curve it has. Despite all the examples in the documentation, I could not understand how to group my events by a tracking_id and return it. Those issues led me to explore other options.
One of the options was MongoDB. It is schema-free, popular, and has an easier learning curve. I was able to quickly write the queries to group the data.
MongoDB Realm provided a way to connect Atlas database with Workers over HTTP. The only downside is the query speed. But, this is, most probably, because I am using a free tier on the shared serverless cluster.
I didn’t put many thoughts into the schema design as the scale I am working with is negligible. But, there are possibilities to scale or tweak database performance. For example, using timeseries collections.
Final results
I have built the MVP version of my web analytics project ![]() It is called “Flarelytics”. The project is open-source on GitHub, so feel free to check.
It is called “Flarelytics”. The project is open-source on GitHub, so feel free to check.
It is deployed for this blog. Below you can find the screenshot of the time-on-page metric for each page on this website. The values are in seconds.
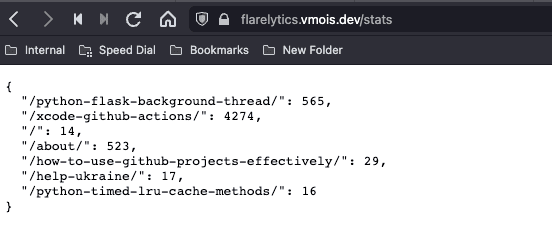
This is a simple metric, but it provides me with some confidence that my content is valuable to the readers.
I do not plan to develop new features anytime soon. Maybe, some smaller improvements and fixes.
Thank you for reading the article!
And, thank you, Krystyna Svirbyy, for reviewing the article.