In this part of the MiWaitWay series, we will improve GTFS-rt (real-time) vehicle location ingestor reliability using Write-Ahead-File (WAF) and Sentry monitoring.
In the previous part, while transforming raw data, I realized that vehicle location data for some hours was missing. Because of that, it is not possible to correctly detect if a bus is near the stop. Therefore, we must ensure all location data is captured before further analysis.
This is your first time hearing about the MiWaitWay project? Want to learn more? Read the introductory article that explains the project’s goal, and read the previous articles to get up to date with the project’s progress.
How GTFS-rt ingestion works? (recap)
Before we work on the ingestor, let me quickly recap how GTFS-rt is ingested in the MiWaitWay project.
The data for the latest vehicle (bus) locations is stored in a Protobuf file that can be accessed on the MiWay transit agency website. The file is updated with the most recent data approximately every 10-15 seconds.
The ingestor container downloads a file every 2 seconds and checks if it differs from the previous one by comparing hashes. If the files differ, it processes location data and saves it in memory. Let’s call this a single chunk.
When a certain number of chunks are collected, they are uploaded to the Google Cloud Storage (GCS) bucket. This is where the responsibilities of the ingestor end. After that, Airflow DAG picks up those files and loads them to BigQuery.
Collecting multiple chunks was done to prevent dealing with tiny files. A single Protobuf file contains a few hundred rows at best. Uploading this chunk to GCS or ingesting it into BigQuery immediately wastes network roundtrip time.
Now that we know how the ingestor works, let’s improve it.
Adding WAF to prevent data loss
With limited resources on the VM and due to unknown errors, the ingestor restarted from time to time, resulting in the loss of the last 20-25 minutes of data (the time it takes to collect 100 chunks) stored in memory. This happened multiple times daily, resulting in significant data gaps. This became the most crucial issue, and to solve it, I reached for a Write-Ahead-File (WAF).
I am familiar with the WAF concept from databases. For example, databases based on LSM-tree store a certain number of new rows in memory before being written onto disks. In case the database is halted, the memory content is lost. This is where WAF comes in. A database writes each incoming change into an append-only file (WAF) before the change is committed. When the database is restarted, the WAF is read, and memory content is restored. Sounds like we have the same issue.
I applied the same concept to the ingestor. The ingestor stores three files as part of “WAF”: Collected chunks The previous Protobuf file hash The number of remaining chunks The files are written after each chunk is collected. In the worst case, the ingestor loses the contents of a single chunk (Protobuf file), which represents only a single point in time of vehicle locations.
I want to avoid jumping into every single line of code due to time constraints. You can find the details of the implementation in those three commits: Introducing WAF; Collect 50 chunks only instead of 100 before uploading them; Fix schema interference in WAF.
Later in the article, we will see how WAF improved the reliability of the ingestor. Now, let’s talk about monitoring.
Setting up monitoring via Sentry
Until this point, I needed to check Docker logs to understand what errors the ingestor had, which became cumbersome. A system to collect the mistakes and send notifications would be great, so I set up Sentry, a popular error-tracking platform.
The initial configuration was easy, and there is little to discuss. You can follow Sentry documentation. The exact changes I made can be found in the commit.
The initial setup worked fine. My only issue was duplicated errors. Because I wanted to keep Docker logs, I manually logged an error and sent an event to Sentry. However, Sentry already captured an error when I used Python’s logging library. After stopping manually sending events to Sentry and switching to logging.exception only, duplicates were eliminated. The error events in Sentry contained my custom error message + the exception context together—fantastic!
In addition, I set a few notification rules, such as reports on all issues in the last 24 hours and, after an unfortunate accident, an alert in case the number of errors in the last 15 minutes exceeds a specific number. This was done to catch early that the ingestor container restarts infinitely due to a continuous error.
Results
Although I was confident the changes improved the ingestor, I still decided to pull some numbers. I left the “new” ingestor running for a week to collect data for comparison. Below, you can see the result plot. The bottom half showcases the number of events collected by the “old” ingestor from Monday to Friday. The upper part contains data collected by the “new” ingestor over the same weekdays but a week later.
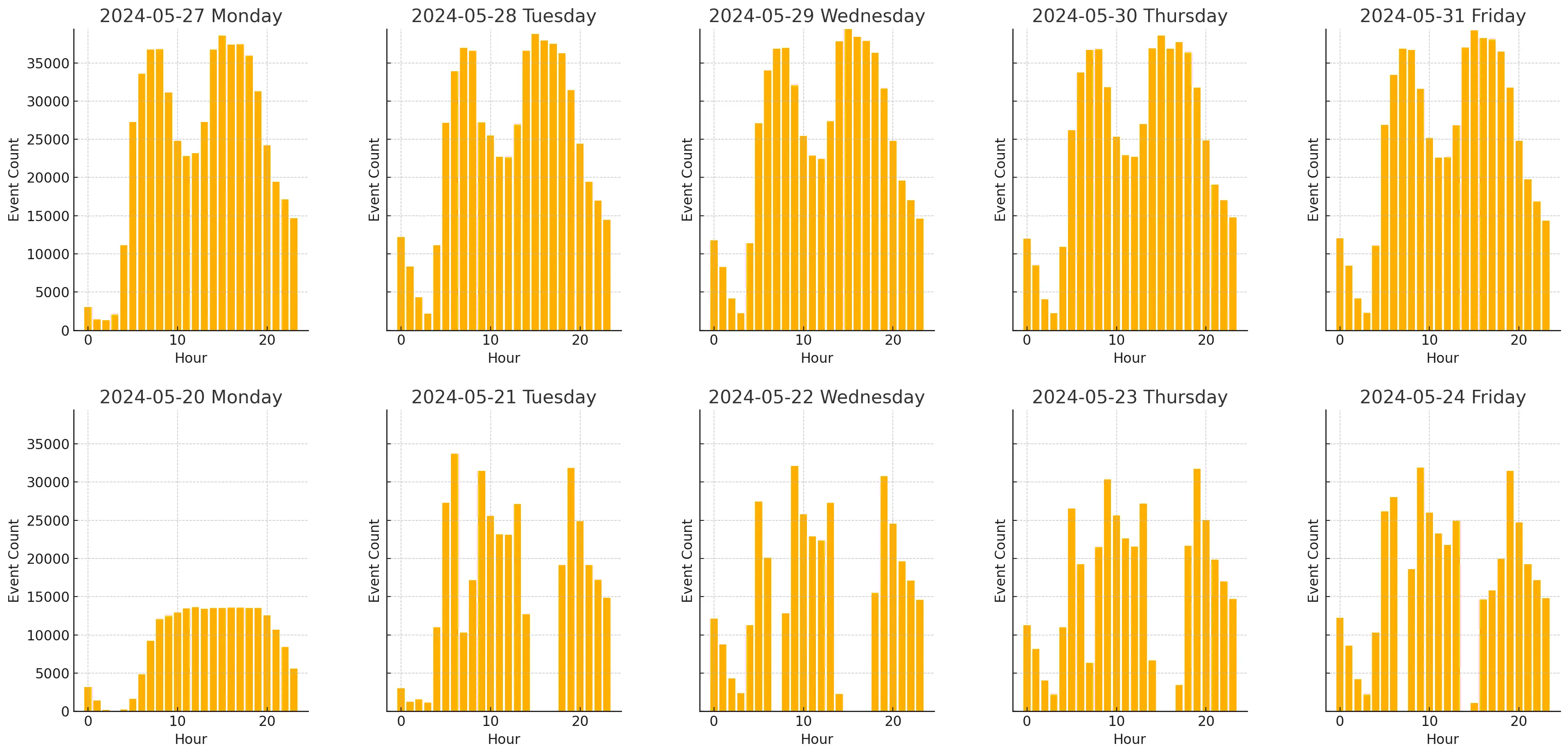
The weekend days for both weeks were not included due to the “old” ingestor breaking over the weekend and some bug fixes for the “new” ingestor.
As you can see, the “new” ingestor collected more data and performed it consistently. This is a good sign that makes me happy.
The query below was used to collect the data then ChatGPT plotted it.
SELECT
TIMESTAMP_TRUNC(DATETIME(timestamp, 'America/Toronto'), HOUR) AS interval_hour,
COUNT(*) AS event_count
FROM
`miwaitway.raw_miway_data.vehicle_position`
WHERE
TIMESTAMP_TRUNC(DATETIME(timestamp, 'America/Toronto'), DAY) >= DATETIME("2024-05-20", 'America/Toronto')
AND
TIMESTAMP_TRUNC(DATETIME(timestamp, 'America/Toronto'), DAY) <= DATETIME("2024-06-01", 'America/Toronto')
GROUP BY
interval_hour
Conclusions
The addition of WAF and Sentry monitoring made the ingestor much better. Now we can continue to the core of the MiWaitWay project - calculating the average wait times at stops. And it will require a lot of SQL :)
In addition, while writing this article, I got an idea for a challenge to build the ingestor for all available GTFS-rt sources while consuming as little memory as possible. This will probably require reaching out to compiled languages such as Go, but this is material for another article.
If you are interested in the details of all my changes, check the PR and the issue related to improvements.
Thank you for your attention. Have a great day!